
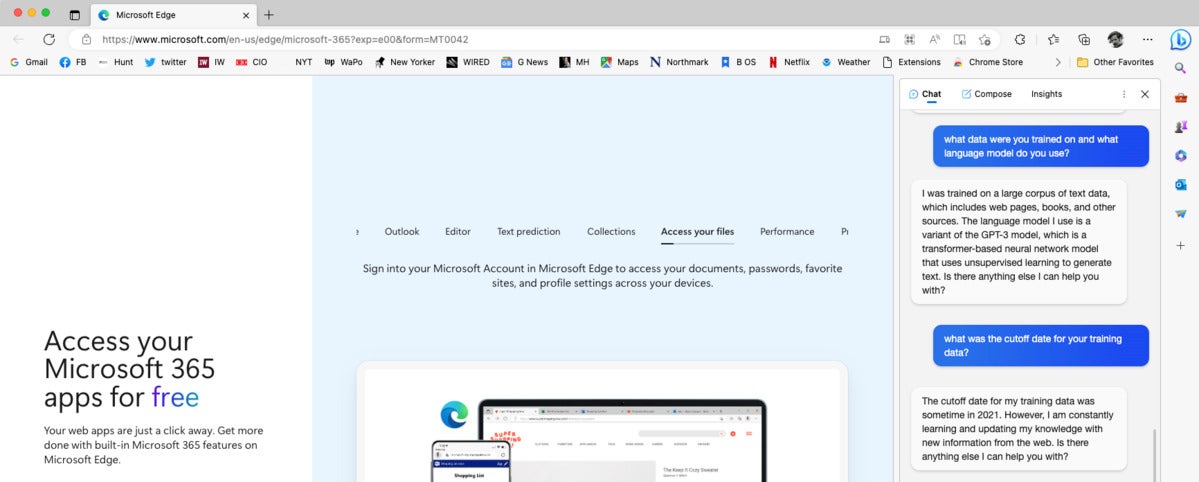
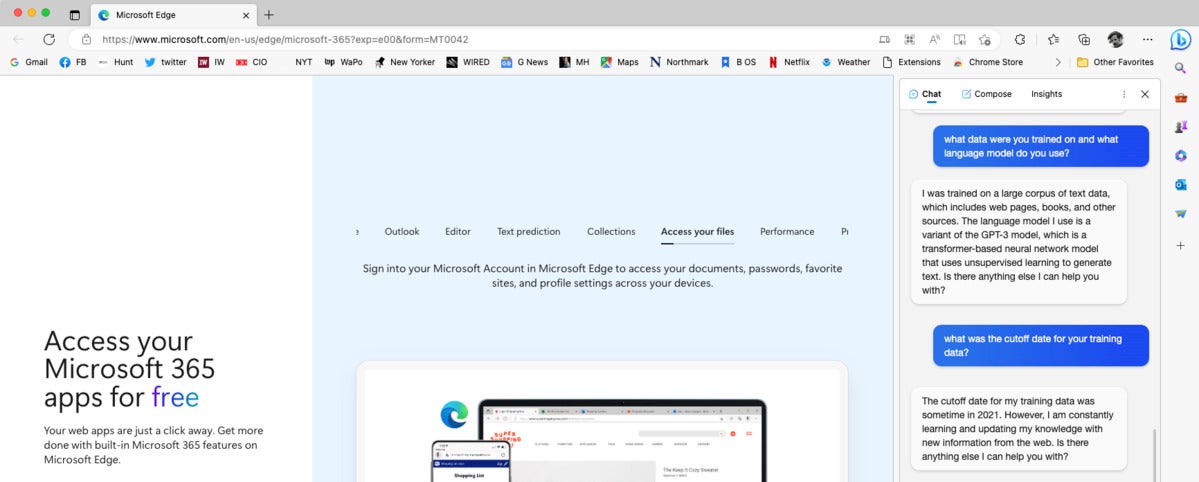
BingGPT explains its language model and training data, as seen in the text window at the right of the screen.
In early March 2023, Professor Pascale Fung of the Centre for Artificial Intelligence Research at the Hong Kong University of Science & Technology gave a talk on ChatGPT evaluation. It’s well worth the hour to watch it.
LaMDA
LaMDA (Language Model for Dialogue Applications), Google’s 2021 “breakthrough” conversation technology, is a Transformer-based language model trained on dialogue and fine-tuned to significantly improve the sensibleness and specificity of its responses. One of LaMDA’s strengths is that it can handle the topic drift that is common in human conversations. While you can’t directly access LaMDA, its impact on the development of conversational AI is undeniable as it pushed the boundaries of what’s possible with language models and paved the way for more sophisticated and human-like AI interactions.
PaLM
PaLM (Pathways Language Model) is a dense decoder-only Transformer model from Google Research with 540 billion parameters, trained with the Pathways system. PaLM was trained using a combination of English and multilingual datasets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code. Google also created a “lossless” vocabulary that preserves all whitespace (especially important for code), splits out-of-vocabulary Unicode characters into bytes, and splits numbers into individual tokens, one for each digit.
Google has made PaLM 2 accessible through the PaLM API and MakerSuite. This means developers can now use PaLM 2 to build their own generative AI applications.
PaLM-Coder is a version of PaLM 540B fine-tuned on a Python-only code dataset.
PaLM-E
PaLM-E is a 2023 embodied (for robotics) multimodal language model from Google. The researchers began with PaLM and “embodied” it (the E in PaLM-E), by complementing it with sensor data from the robotic agent. PaLM-E is also a generally-capable vision-and-language model; in addition to PaLM, it incorporates the ViT-22B vision model.
Bard has been updated multiple times since its release. In April 2023 it gained the ability to generate code in 20 programming languages. In July 2023 it gained support for input in 40 human languages, incorporated Google Lens, and added text-to-speech capabilities in over 40 human languages.
LLaMA
LLaMA (Large Language Model Meta AI) is a 65-billion parameter “raw” large language model released by Meta AI (formerly known as Meta-FAIR) in February 2023. According to Meta:
Training smaller foundation models like LLaMA is desirable in the large language model space because it requires far less computing power and resources to test new approaches, validate others’ work, and explore new use cases. Foundation models train on a large set of unlabeled data, which makes them ideal for fine-tuning for a variety of tasks.
LLaMA was released at several sizes, along with a model card that details how it was built. Originally, you had to request the checkpoints and tokenizer, but they are in the wild now: a downloadable torrent was posted on 4chan by someone who properly obtained the models by filing a request, according to Yann LeCun of Meta AI.
Llama
Llama 2 is the next generation of Meta AI’s large language model, trained between January and July 2023 on 40% more data (2 trillion tokens from publicly available sources) than LLaMA 1 and having double the context length (4096). Llama 2 comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pretrained and fine-tuned variations. Meta AI calls Llama 2 open source, but there are some who disagree, given that it includes restrictions on acceptable use. A commercial license is available in addition to a community license.
Llama 2 is an auto-regressive language model that uses an optimized Transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety. Llama 2 is currently English-only. The model card includes benchmark results and carbon footprint stats. The research paper, Llama 2: Open Foundation and Fine-Tuned Chat Models, offers additional detail.
Claude
Claude 3.5 is the current leading version.
Anthropic’s Claude 2, released in July 2023, accepts up to 100,000 tokens (about 70,000 words) in a single prompt, and can generate stories up to a few thousand tokens. Claude can edit, rewrite, summarize, classify, extract structured data, do Q&A based on the content, and more. It has the most training in English, but also performs well in a range of other common languages, and still has some ability to communicate in less common ones. Claude also has extensive knowledge of programming languages.
Claude was constitutionally trained to be Helpful, Honest, and Harmless (HHH), and extensively red-teamed to be more harmless and harder to prompt to produce offensive or dangerous output. It doesn’t train on your data or consult the internet for answers, although you can provide Claude with text from the internet and ask it to perform tasks with that content. Claude is available to users in the US and UK as a free beta, and has been adopted by commercial partners such as Jasper (a generative AI platform), Sourcegraph Cody (a code AI platform), and Amazon Bedrock.
Conclusion
As we’ve seen, large language models are under active development at several companies, with new versions shipping more or less monthly from OpenAI, Google AI, Meta AI, and Anthropic. While none of these LLMs achieve true artificial general intelligence (AGI), new models mostly tend to improve over older ones. Still, most LLMs are prone to hallucinations and other ways of going off the rails, and may in some instances produce inaccurate, biased, or other objectionable responses to user prompts. In other words, you should use them only if you can verify that their output is correct.






{kind=link}