
Anyone working in DevOps today would likely agree that codifying resources makes it easier to observe, govern, and automate. However, most engineers would also acknowledge that this transformation brings with it a new set of challenges.
Perhaps the biggest challenge of IaC operations is drifts — a scenario where runtime environments deviate from their IaC-defined states, creating a festering issue that could have serious long-term implications. These discrepancies undermine the consistency of cloud environments, leading to potential issues with infrastructure reliability and maintainability and even significant security and compliance risks.
In an effort to minimize these risks, those responsible for managing these environments are classifying drift as a high-priority task (and a major time sink) for infrastructure operations teams.
This has driven the growing adoption of drift detection tools that flag discrepancies between the desired configuration and the actual state of the infrastructure. While effective at detecting drift, these solutions are limited to issuing alerts and highlighting code diffs, without offering deeper insights into the root cause.
Why Drift Detection Falls Short
The current state of drift detection stems from the fact that drifts occur outside the established CI/CD pipeline and are often traced back to manual adjustments, API-triggered updates, or emergency fixes. As a result, these changes don’t usually leave an audit trail in the IaC layer, creating a blind spot that limits the tools to just flagging code discrepancies. This leaves platform engineering teams to speculate about the origins of drift and how it can best be addressed.
This lack of clarity makes resolving drift a risky task. After all, automatically reverting changes without understanding their purpose — a common default approach — could be opening a can of worms and can trigger a cascade of issues.
One risk is that this could undo legitimate adjustments or optimizations, potentially reintroducing problems that were already addressed or disrupting the operations of a valuable third-party tool.
Take, for example, a manual fix applied outside the usual IaC process to address a sudden production issue. Before reverting such changes, it’s essential to codify them to preserve their intent and impact or risk prescribing a cure that could turn out to be worse than the illness.
Detection Meets Context
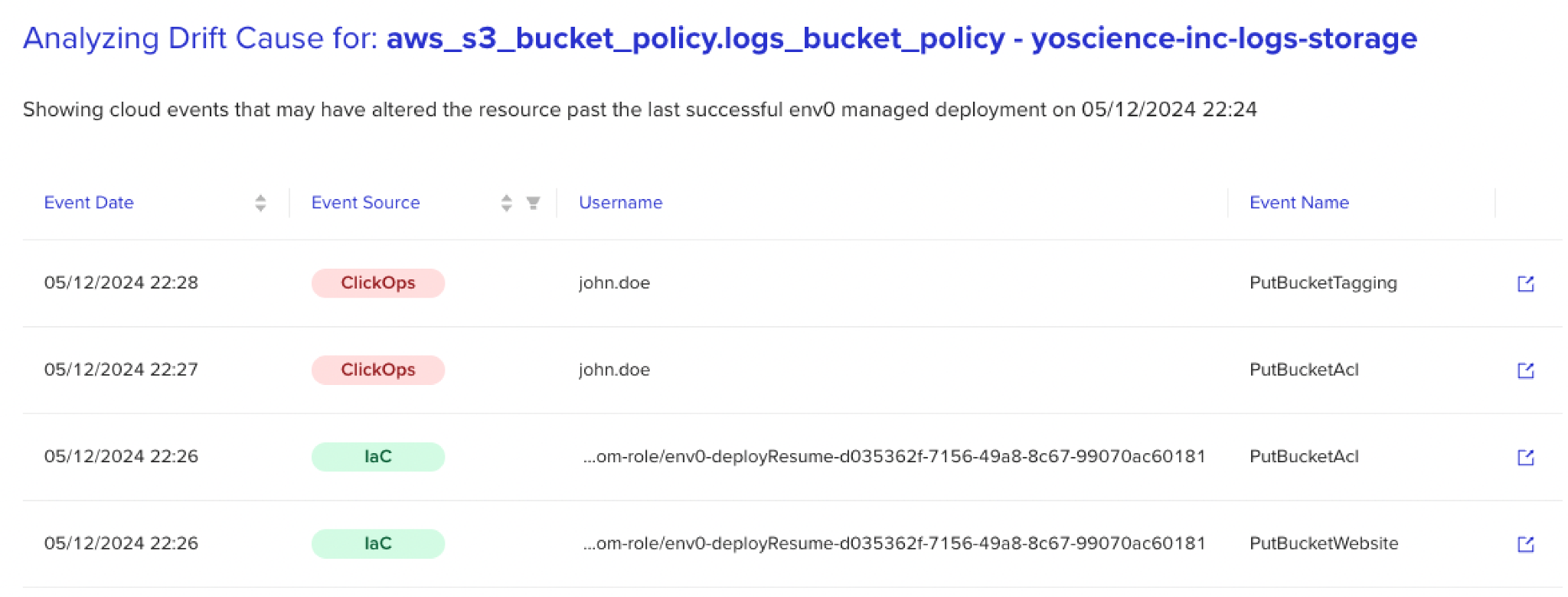
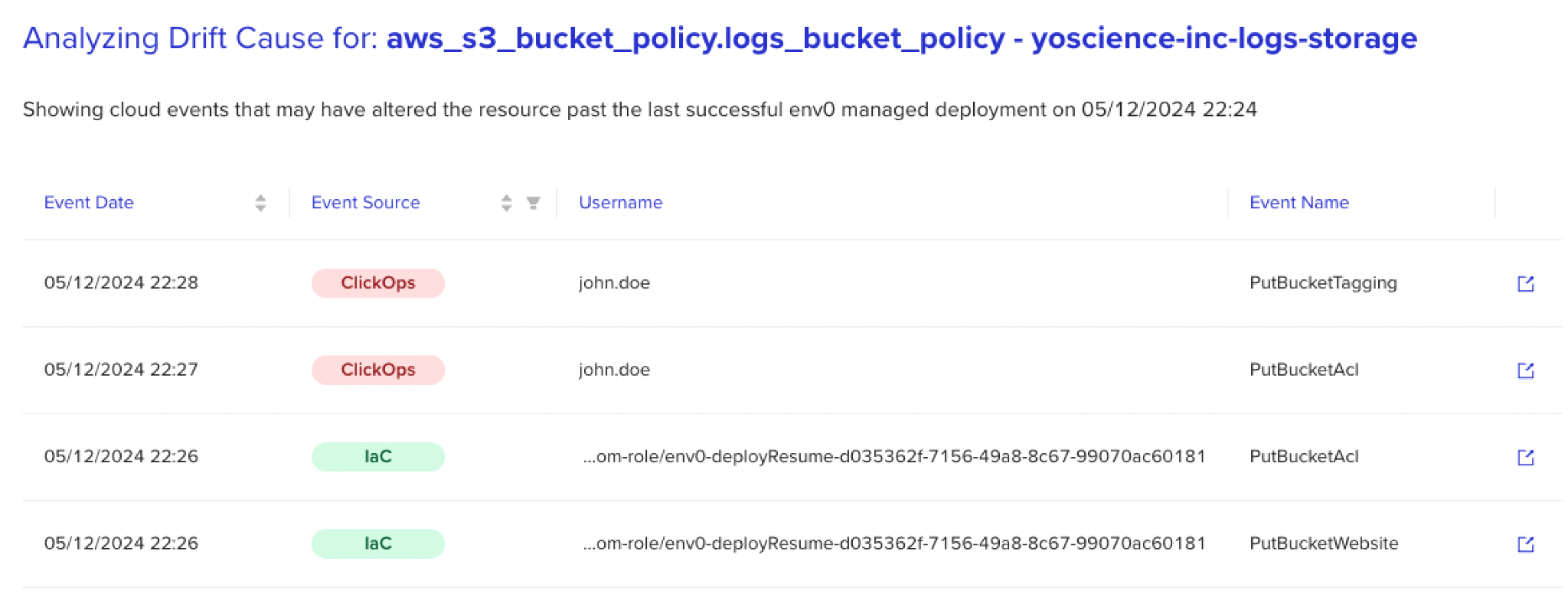
Seeing organizations grapple with these dilemmas has inspired the concept of ‘Drift Cause.’ This concept uses AI-assisted logic to sift through large event logs and provide additional context for each drift, tracing changes back to their origin — revealing not just ‘what’ but also ‘who,’ ‘when,’ and ‘why.’
This ability to process non-uniform logs in bulk and gather drift-related data flips the script on the reconciliation process. To illustrate, let me take you back to the scenario I mentioned earlier and paint a picture of receiving a drift alert from your detection solution — this time with added context.
Now, with the information provided by Drift Cause, you can not only be aware of the drift but also zoom in to discover that the change was made by John at 2 a.m., right around the time the application was handling a traffic spike.
Without this information, you might assume the drift is problematic and revert the change, potentially disrupting critical operations and causing downstream failures.
With the added context, however, you get to connect the dots, reach out to John, confirm that the fix addressed an immediate issue, and decide that it shouldn’t be blindly reconciled. Moreover, using this context, you can also start thinking ahead and introduce adjustments to the configuration to add scalability and prevent the issue from recurring.
This is a simple example, of course, but I hope it does well to show the benefit of having additional root cause context — an element long missing from drift detection despite being standard in other areas of debugging and troubleshooting. The goal, of course, is to help teams understand not just what changed but why it changed, empowering them to take the best course of action with confidence.
Beyond IaC Management
But having additional context for drift, as important as it may be, is only one piece of a much bigger puzzle. Managing large cloud fleets with codified resources introduces more than just drift challenges, especially at scale. Current-gen IaC management tools are effective at addressing resource management, but the demand for greater visibility and control in enterprise-scale environments is introducing new requirements and driving their inevitable evolution.
One direction I see this evolution moving toward is Cloud Asset Management (CAM), which tracks and manages all resources in a cloud environment — whether provisioned via IaC, APIs, or manual operations — providing a unified view of assets and helping organizations understand configurations, dependencies, and risks, all of which are essential for compliance, cost optimization, and operational efficiency.
While IaC management focuses on the operational aspects, Cloud Asset Management emphasizes visibility and understanding of cloud posture. Acting as an additional observability layer, it bridges the gap between codified workflows and ad-hoc changes, providing a comprehensive view of the infrastructure.
1+1 Will Equal Three
The combination of IaC management and CAM empowers teams to manage complexity with clarity and control. As the end of the year approaches, it’s ‘prediction season’ — so here’s mine. Having spent the better part of the last decade building and refining one of the more popular (if I may say so myself) IaC management platforms, I see this as the natural progression of our industry: combining IaC management, automation, and governance with enhanced visibility into non-codified assets.
This synergy, I believe, will form the foundation for a better kind of cloud governance framework — one that is more precise, adaptable, and future-proof. By now, it’s almost a given that IaC is the bedrock of cloud infrastructure management. Yet, we must also acknowledge that not all assets will ever be codified. In such cases, an end-to-end infrastructure management solution can’t be limited to just the IaC layer.
The next frontier, then, is helping teams expand visibility into non-codified assets, ensuring that as infrastructure evolves, it continues to perform seamlessly — one reconciled drift at a time and beyond.







{kind=link}