
Organizations globally are leveraging the capabilities of Large Language Models (LLMs) to enhance their chatbot functionalities. These advanced chatbots are envisioned not just as tools for basic interaction but as sophisticated systems capable of intelligently accessing and processing a diverse array of internal organizational assets. These assets include detailed knowledge bases, frequently asked questions (FAQs), Confluence pages, and a myriad of other organizational documents and communications.
This strategy is aimed at tapping into the rich vein of internal knowledge, ensuring more accurate, relevant, and secure interactions. However, this ambitious integration faces significant hurdles, notably in the realms of data security, privacy, and the avoidance of erroneous or “hallucinated” information, which are common challenges in AI-driven systems. Moreover, the practical difficulties of retraining expansive LLMs, considering the associated high costs and computational requirements, further complicate the situation. This article delves into a strategic solution to these challenges: the implementation of Retrieval-Augmented Generation (RAG) models in conjunction with LLMs, complemented by the innovative use of session-based context management through Redis cache.
The Challenge: Contextual Continuity and Resource Retrieval
Organizations face a significant challenge in chatbot implementation: maintaining context in conversations, especially when combining RAG model outputs with LLM enhancements. Traditional LLMs, when tasked with retrieving answers from organizational resources, often treat each query as an independent interaction. This leads to a disjointed conversation flow, especially evident in follow-up questions even within the same session.
Example 1: (Without Session Context)
- User: How do I change the RAM in my laptop?
- Chatbot: Here are the steps to change the RAM in your laptop…
- User (Follow-up): I tried these steps, but it didn’t work.
- Chatbot (Without Session Context): Can you specify your issue?
The Solution: Combining RAG Models With Redis Cache for Contextual Conversations
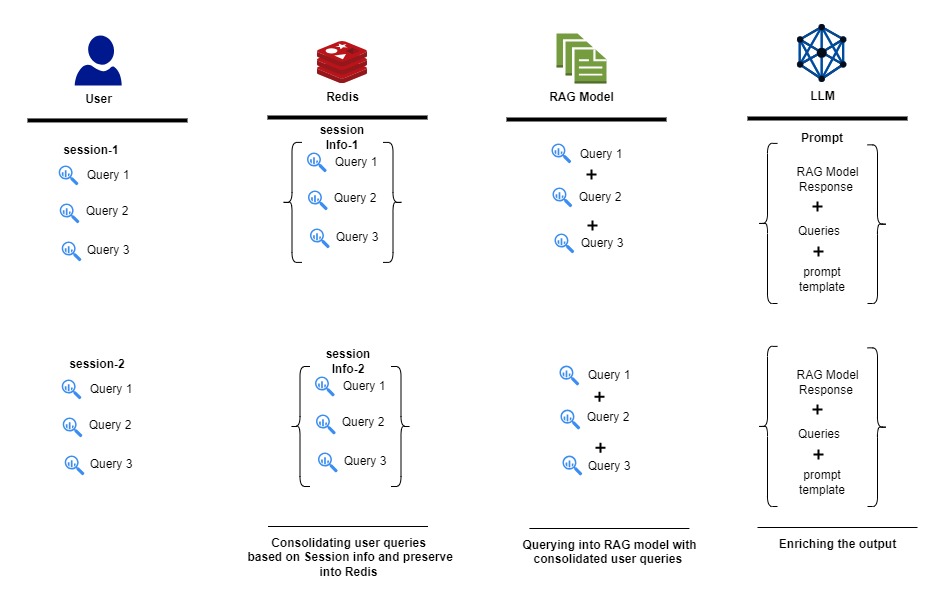
- Consolidating Queries in Sessions: The crux of the solution lies in consolidating all queries within a user session. Each question a user asks during a session is recorded and considered in the context of previous questions.
This consolidation allows the chatbot, powered by RAG models and LLMs, to generate responses that are contextually informed and relevant to the ongoing dialogue.
- Redis for Efficient Session Management: Redis cache is employed to manage and store these session-based queries efficiently. It ensures rapid access to session data, thus facilitating quick and context-aware responses from the chatbot.
- Operational Benefits: This approach not only addresses the issue of contextual continuity but also enhances the security and privacy of user interactions, as the data retrieval is confined to the organization’s internal resources.
To better illustrate the effectiveness of this solution, consider the following examples with session context:
Example 2 (With Session Context)
- User: How do I change the RAM in my laptop?
- Chatbot: Here are the steps to change the RAM in your laptop…
- User (Follow-up): I tried these steps, but it didn’t work.
- Chatbot (With Session Context): It seems there’s a hiccup in the RAM change process. Let’s dive deeper. Did you ensure the laptop was powered off?
In this example, the chatbot recalls the user’s initial query about changing RAM, allowing it to provide a more helpful and contextually relevant follow-up response.
Example 3 (With Session Context)
- User: Can you help me with my email setup?
- Chatbot: Certainly! Are you using our internal email client or a third-party service?
- User (Follow-up): The internal client.
- Chatbot (With Session Context): Perfect, I can assist with that. For setting up the internal email client, here are the steps you need to follow…
Here, the chatbot demonstrates an understanding of the ongoing conversation, offering a seamless and intuitive response that builds upon the user’s previous query.
High-Level Design

Sample Code for Session-Based Query Management
import redis
import json
# Setting up a Redis connection
redis_client = redis.StrictRedis(host="localhost", port=6379, db=0, decode_responses=True)
# Session management function to consolidate user queries
def manage_chat_session(session_id, user_query=None):
# Retrieve existing session data
session_data = json.loads(redis_client.get(session_id) or "[]")
# Append new query to the session
if user_query:
session_data.append(user_query)
redis_client.set(session_id, json.dumps(session_data))
return session_data
# Demonstrating session-based query consolidation
session_id = "user123_session"
manage_chat_session(session_id, "How to change laptop RAM?")
manage_chat_session(session_id, "Encountered an issue with the steps.")
consolidated_queries = manage_chat_session(session_id)
print("Session-based Consolidated Queries:", consolidated_queries)
*Note: The provided sample code is a basic illustration, intended to be adapted for specific organizational requirements and use cases.
Conclusion
The combination of RAG models with LLMs, along with the use of Redis cache for managing conversations, is a big step forward in chatbot technology. This method improves how users interact with chatbots, making conversations more relevant and easier to follow. It also helps in efficiently handling lots of conversation data. As we move forward in the world of AI, these kinds of improvements are important for making smart systems that can communicate with people in a natural way.






{kind=link}