
This article was co-authored by Stephan Lips, Devin Cunningham and Justin Hoang of Procore and is a preview of their talk for SLOconf 2023 on May 15-18, 2023. To watch this talk and many more like it, register for free at sloconf.com.
By managing service level objectives (SLOs) as code, we can co-locate SLO definitions and ownership with the product code and team. This supports horizontal scaling of SLO ownership while establishing a single source of truth and adding transparency, integrating with the code management process, and creating an audit trail for SLOs.
When you measure the reliability of hundreds or even thousands of products and services across an enterprise, ownership of SLOs should not reside with a single team. There are a few aspects that make scaling SLO ownership horizontally across teams much more efficient: A standardized SLO management platform, process architecture and automation across the enterprise. Managing SLOs-as-code alongside product code is a step towards 360° product ownership and enables us to automate SLO updates via continuous integration.
Objectives and Architecture
The larger objective behind the SLOs-as-code approach is to move towards 360° product ownership. At Procore, teams own their product’s code and processes, including aspects like testing, performance, reliability, automated deployment pipelines and deployment configurations. Adding SLO ownership to a team’s portfolio will also help improve product reliability.
Implementing SLOs-as-code involves three architectural components, which will be discussed in detail in their own respective sections. In summary, these components are:

|
SLO Objects and Definitions
Procore’s Observability team has designed our SLO-as-code approach to scale with Procore’s growing number of teams and services. Choosing YAML as the source of truth allows Procore a scalable approach for the company through centralized automation. Following the examples put forth by openslo.com and embracing a ubiquitous language like YAML helps avoid adding the complexities of Terraform for development teams and is easier to embed in every team’s directories. We used a GitOps approach to infrastructure-as-code (IaC) to create and maintain our Nobl9 resources.
The Nobl9 resources can be defined as YAML configuration (config) files. In particular, one can declaratively define a resource’s properties (in the config file) and have a tool read and process that into a live and running resource. It’s important to draw a distinction between the resource and its configuration, as we’ll be discussing both throughout this article. All resources, from projects (the primary grouping of resources in Nobl9) to SLOs, can be defined through YAML.
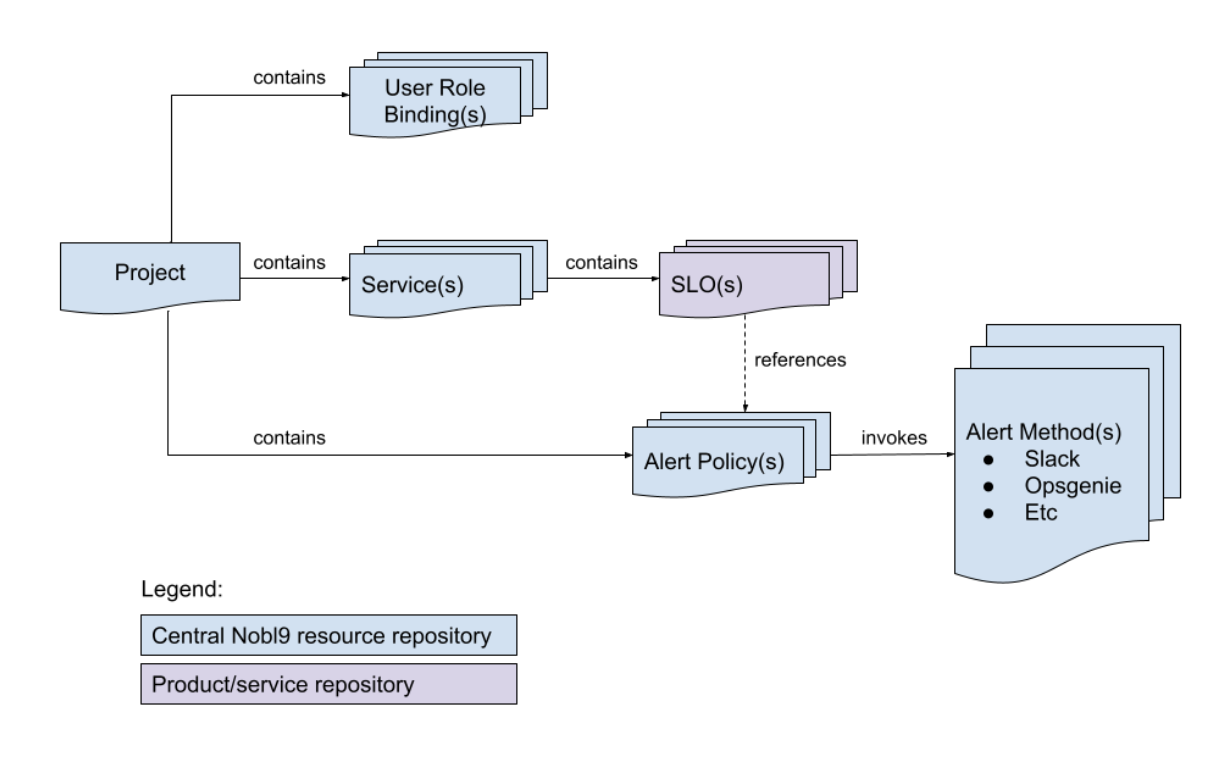
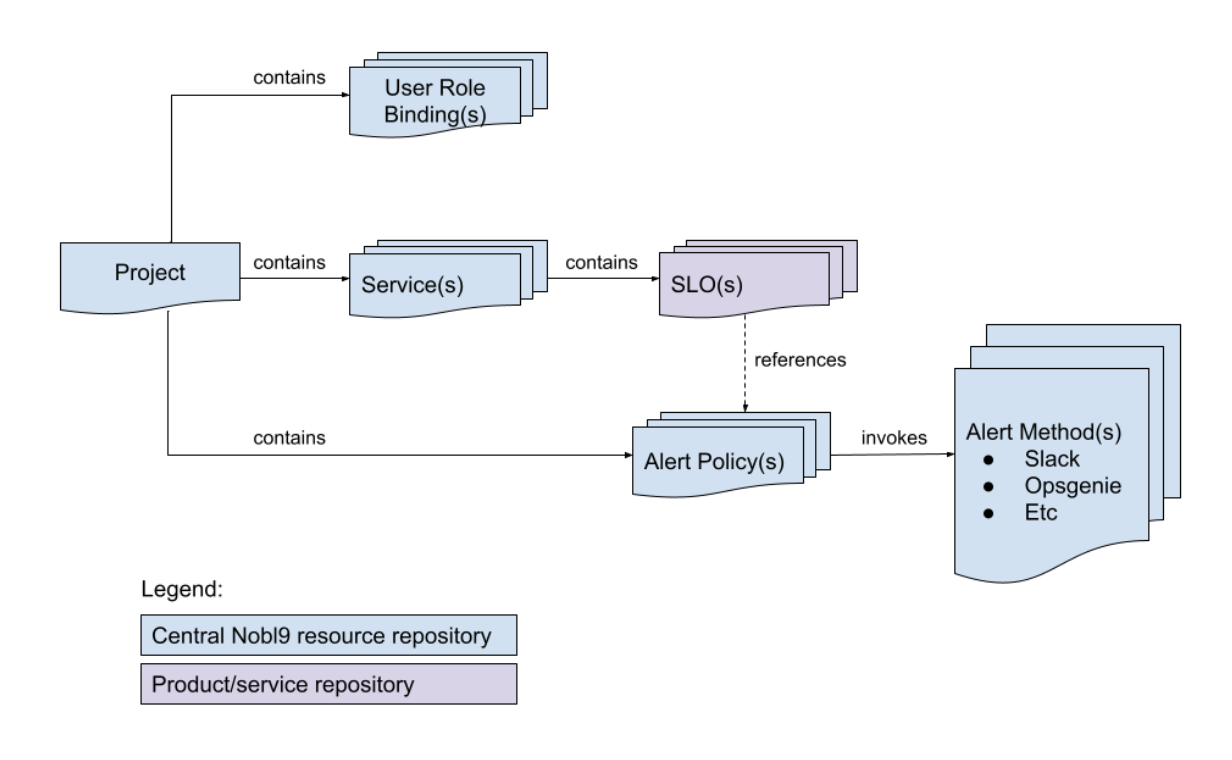
Figure 2. A simple visualization of Nobl9 object relationships. A Project is a top-level object. Projects contain Services, SLOs are attached to Services, and SLOs can trigger alerts via project-scoped Alert Policies. Finally, Role Bindings define who has access to the Project contents.
Procore adopted a hybrid approach to organizing our Nobl9 configuration so that the observability team can review systemic changes while teams still own changes to their service SLOs. A separate central repository is the source of truth for all other Nobl9 configurations, such as Project and Alert Policy definitions. As projects have a one-to-many relationship with their services, it would quickly become a game of “guess where” if the project configuration were defined within one of its service repositories. The central repository is owned by the observability team and allows us to manage permissions through pull request reviews submitted by product teams for their non-SLO Nobl9 resources. Once requests are merged, our automation applies the changes. The SLO definitions are co-located with the service’s code. Teams self-regulate these resources to maintain their SLOs internally.
Automation
Automating the creation and modification of Nobl9 resources is essential to Procore — it makes iterating on the deployment process quick and painless for our engineering teams. Automation removes human error and possible complications that usually come along with manually applying config files via CLI tools.
With that in mind, the observability team created a CI job/workflow that our engineering teams copy into their project repo during their SLOs-as-code onboarding. Procore’s CI job uses the Nobl9 sloctl docker image, so we do not have to install the sloctl CLI tool in our CI containers. We configured this job to only apply the configs that have been added or updated, which helps to future-proof our pipeline as we scale the number of our SLO configs.

Figure 3: SLOs-as-code Automation Workflow
This requires the following steps in the workflow:
- An engineer creates or modifies a config and commits the changes to GitHub.
- The engineer opens a PR, gets reviews and merges their changes into the main branch.
- CI picks up the changes in GitHub and kicks off the following steps:
1. Using git diff and regex pattern matching, we figure out what configs have been added or changed from the most recent merge to main:
|
#!/bin/bash |
2. We loop over the added/changed configs and run sloctl apply using the nobl9/sloctl docker image, which updates our resources in Nobl9:
|
#!/bin/bash |
3. We use the same workflow in our centralized IaC repo that manages our projects, services, role-binding and alert policy configs.
Common Platform
Our platform requires another key feature for SLOs-as-code to work: We need to be able to consolidate different observability data sources and telemetry streams that power SLIs. This platform needs to support standardized data formats to define SLOs and related entities, such as alert policies for different conditions and trends, while allowing for the management of these formats via automation. We evaluated three vendors that offered SLO solutions, and only Nobl9 met all our requirements, which extended beyond the SLOs-as-code topic of this article.
Observations
Adopting SLOs-as-code can be impeded by three particular barriers of entry: New tooling (Nobl9 platform), data and format (SLO configs and resources) and process. To drive adoption, we have designed a self-service model supported by an open-door consulting practice. While this is an ongoing learning process for all involved, we are seeing early signs of success of an approach that uses:
- Detailed, step-by-step instructions, including code snippets and templates.
- Screencast tutorials supplementing the instructions.
- Initial face-to-face, white-glove meetings to explain concepts and provide demos. The personal experience and conversation in our experience created considerable enthusiasm and goodwill among our teams. It proved to be a much better approach than just pointing them to documentation.
- Fast feedback cycles with onboarding teams to improve instructions.
Quite frequently, teams stated their primary challenges were not the technical aspects of SLOs-as-code discussed in this article, but how to design and improve on meaningful SLOs. We addressed this by authoring articles like Black Box SLIs and other internal resources for guidance. While posts can be a useful tool, we found that working with teams and discussing how their product impacts the user experience was more beneficial to modeling their SLOs using observability data.
Last but not least, we are integrating with our embedded SRE (ESRE) team to help onboard more services. When a product team engages with ESRE on their deployment strategy and configuration, ESRE also discusses onboarding to SLOs-as-code and basic SLOs, such as error rate or duration.







{kind=link}