
Large language models (LLMs) don’t need an introduction anymore. Just as “Did you Google it?” was the question 10 years ago, now it’s “Did you ask ChatGPT?” As organizations increasingly adopt LLMs, the number of people interacting with them, directly or indirectly, is also increasing exponentially.
Today, the use of these models is no longer limited to tech. Healthcare, transportation, media, and many other industries are adopting them. However, along with adoption, one more thing that has grown is security concerns.
There are several instances where requesting the LLM model for a piece of information or tricking it can result in giving out sensitive PII (Personally Identifiable Information). For example, the result of a “divergence attack” where the model was instructed to repeat a word forever caused it to output email addresses, phone numbers, and names.
In another instance, while Samsung employees were using ChatGPT to debug something, they also ended up giving it sensitive organization data. Sensitive Information Disclosure, as defined by OWASP (Open Worldwide Application Security Project), is such a big problem that it has been on the organization’s top ten list for more than two years. So, what are the mitigations for this? How do we make sure the model does not emit sensitive information?
If your model is hosted by a third-party company, meaning if you are a customer using ChatGPT, then you don’t have much control over how the model behaves. In this scenario, the only solution would be to avoid inputting sensitive information altogether.
On the other hand, if you are hosting the model, let’s look at the scenarios and corresponding mitigations:
Scenario 1: Training the Model on Your Organization’s Data (Fine-Tuning)
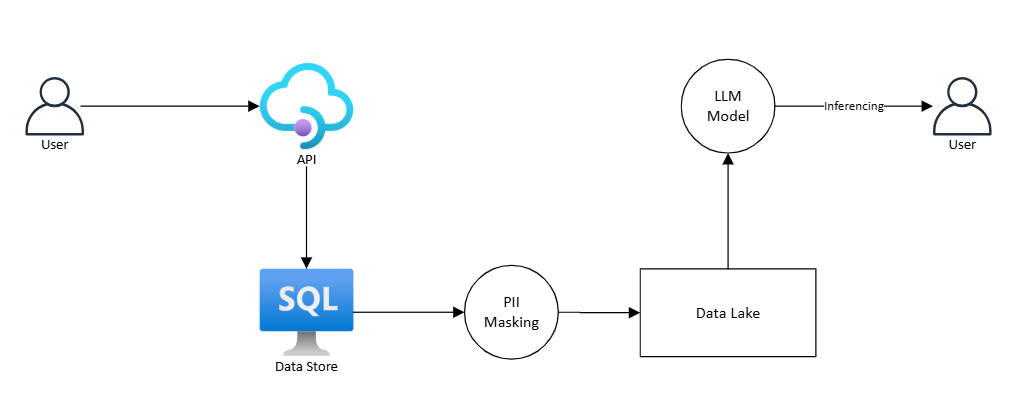
Here, we take a pre-trained model and further train it on a specific dataset that reflects closer to what your organization does. If the data isn’t properly masked, we risk exposing sensitive data. One way to protect against this is to anonymize the sensitive information and then feed it to the model.
For example, if a data lake is used in which the model is being trained, make sure to use masking or anonymizing libraries and that the PII data is masked before putting it into the data lake.
Example Architecture

Looking at the example architecture, whatever job is dumping the data from the data store to the data lake can perform this masking and then do the ingestion.
Scenario 2: Retrieving Data Using RAG (Retrieval-Augmented Generation)
An example use case can be a chatbot designed to answer human resource-related questions for your employees. In this case, all the documents are vectorized and stored in a vector store. The model uses the information in the store to answer user queries.
If the documents contain PII data, there is a high risk of the model being exposed when proper guardrails are not in place. So, let’s look at what we can do to mitigate this.
- One guardrail that could be employed here is like scenario 1, where before ingesting to the datastore, the sensitive data can be anonymized.
- The second option can be to filter out the data coming from the LLM before passing it to the user. Tools like AWS Comprehend, Microsoft Presidio, or the Cloud Native Dapr Conversation AI component can help with this.

For better understanding, let’s use Dapr (Distributed application runtime) and see how we can filter out the sensitive information.

Dapr’s conversation API offers a setting to filter out PII data in the request and response. Currently, it provides filtering out phone numbers, email addresses, IP addresses, street addresses, credit cards, Social Security numbers, ISBNs, and MAC address filtering capabilities. Now, let’s look at the conversation API in action.
This demonstration will be on Windows using .NET. For other platforms, follow the platform-specific steps here.
Step 1
Install the Dapr CLI.
powershell -Command "iwr -useb https://raw.githubusercontent.com/dapr/cli/master/install/install.ps1 | iex"
Step 2
Run dapr init in PowerShell.
Step 3
Dapr has a bunch of building blocks, and each of them is stored as YAML files in the %UserProfile%\.dapr directory.
Step 4
Create a conversation.yml file in the same directory with the following settings.
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: openai
spec:
type: conversation.openai
metadata:
- name: key
value: "YOUR_OPENAI_KEY"
- name: model
value: gpt-4o-mini
- name: cacheTTL
value: 10mThe API Key for OpenAI can be obtained from here.
Step 5
Run Dapr locally with the following command:
dapr run --app-id myapp --dapr-http-port 3500 --dapr-grpc-port 4500Step 6
Include the following package in your csproj. The latest versions can be found here.
<PackageReference Include="Dapr.AI" Version="1.15.2" />Step 7
Insert the following code block. There are also some emails, IP addresses, and phone numbers.
using Dapr.AI.Conversation;
using Dapr.AI.Conversation.Extensions;
Environment.SetEnvironmentVariable("DAPR_HTT_PORT", "3500");
Environment.SetEnvironmentVariable("DAPR_GRPC_PORT", "4500");
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDaprConversationClient();
var app = builder.Build();
var conversationClient = app.Services.GetRequiredService<DaprConversationClient>();
var response = await conversationClient.ConverseAsync("openai",
new List<DaprConversationInput>
{
new DaprConversationInput(
"Hello LLM, How are you",
DaprConversationRole.Generic, true),
new DaprConversationInput(
"Can you return back this same string ?" +
"Microservices, Microservices, Microservices, smart@gmail.com, dzone@gmail.com, +1234567890, +2328192811, 127.0.0.1", DaprConversationRole.Generic, true
)
});
Console.WriteLine("Received the following response from the LLM:");
foreach (var resp in response.Outputs)
{
Console.WriteLine($"{resp.Result}");
}Step 8
This is the final output.

From the screenshot, we can see that Dapr was able to mask the PII information, filtering out the sensitive data (<EMAIL_ADDRESS>, <PHONE_NUMBER>).
Final Thoughts
Just as the proverb “Prevention is better than cure” suggests, it is best to filter out sensitive information before it enters your model. Along with that, monitoring the output from the model will act as an additional protection layer. Implementing such filters at both input and output stages ensures that sensitive data is neither ingested nor leaked.






{kind=link}