

Tabnine this week previewed an ability to track the provenance and attribution of code that if generated by a large language model (LLM) might create potential liabilities for organizations that included it as an application.
Company president Peter Guagenti said that as organizations rely more on code generated by AI platforms, they are becoming concerned they may wind up inadvertently including intellectual property that belongs to either an individual developer or third-party organizations in their code.
This has become an issue because general-purpose LLMs are typically trained using code pulled from across the web under the assumption that data is available for fair use. However, there are now several legal cases alleging that builders of LLMs have violated the copyrights of developers and other forms of content to train their AI models.


The code and provenance attribution feature that is being added to a Tabnine platform uses LLMs to automatically generate code, to make it simpler to identify potential issues involving copyrights that the platform discovers in public repositories such as GitHub, says Guagenti. That capability not only flags output that exactly matches open source code on GitHub but also any functional or implementation matches. Tabnine is also working toward adding a capability that identifies specific repositories, such as those maintained by competitors, to further check the provenance of code. Additionally, Tabnine plans to add censorship capability, allowing Tabnine administrators to remove matching code before it is shared with a developer.
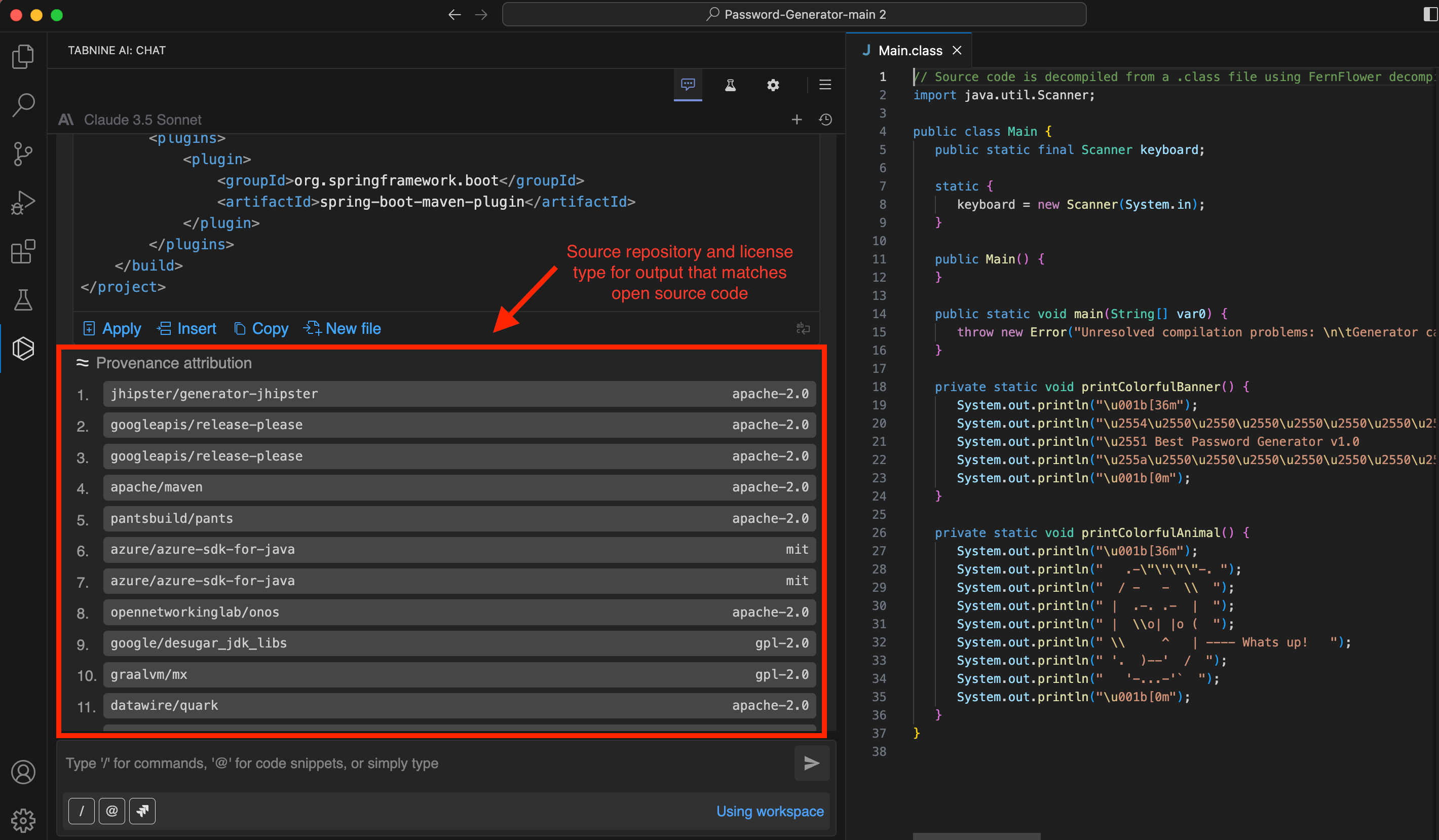
Once notified of any potential issue, it will then be up to each application development team to decide to what degree they might be comfortable including that code in an application environment, he added. If an issue is discovered after an application has been deployed, the effort required to remove that code across a distributed computing environment could be significant.
Tabnine provides application development teams with access to both LLMs it has trained as well as third-party LLMs. The LLMs created by Tabnine, in contrast, have been trained exclusively on code that is permissively licensed.
AI is already being widely used by software engineers to create code for multiple types of use cases. A Techstrong Research survey finds a third (33%) of respondents work for organizations that make use of AI to build software, while another 42% are considering it. Only 6% said they have no plans to use AI. However, the survey also finds only 9% have fully integrated AI into their DevOps pipelines. Another 22% have partially achieved that goal, while 14% are doing so only for new projects. A total of 28% said they expect to integrate AI into their workflows in the next 12 months.
Regardless of the level of enthusiasm for AI, DevOps teams will be well advised to proceed with caution until case law surrounding AI copyrights is thoroughly settled. After all, even if the providers of AI platforms indemnify an organization from any potential financial liability, removing code from an application after it’s been deployed will cause a level of disruption that everyone involved would, if possible, much rather avoid.







{kind=link}